A brief outline of textual scholarship
Peisistratus (560–527 BCE) orders the 'official' text of Homer. The primary challenge was to build a coherent text from myriad versions spoken by the rhapsodes. This could be a viable beginning of textual criticism, i.e., being aware of variance and attending to authenticity and authority (whatever those terms mean). (Discuss!)
Lycurgus (c. 390–324 BCE) arranges for single texts of Aeschylus, Sophocles, and Euripedes to be deposited into Athenian archives.
The history of textual editing is a history of arguments about the meaning of terms such as authenticity and authority. It is also a record of humans grappling with the contingencies of cultural imagination, tradition, and artifacts.
What is the textus receptus? When mistakes in a received (published) edition prevail: E.g., Falstaff "babbl'd o' green fields" (Shakespeare, Henry V); "soiled fish of the sea" (Melville, White-Jacket).
Library of Alexandria: manuscript copying was a common practice, since all incoming ships had to declare any manuscripts in their possession. Any manuscripts declared would then be copied and deposited in libraries. Their copies were only labeled differently if they had differences.
The birth of collation as an editorial practice; and dealing with analogy versus anomaly: the Alexandrians sought to emend texts that had, in their judgment, corruptions. Their practice is idealistic: the best text is not based on any actual document but rather a new document that seeks to bring out the best readings from all the extant texts.
Pergamum, the other civic rival to Alexandria, switched to using parchment (animal skin) after Alexandria banished papyrus exports during a trade conflict. Generally, the Pergamanian scholars accepted the necessity of corruption and sought to identify the "best text" based on a careful examination of all surviving witnesses. The "best text" would be based on an actual historical document, rather than the Alexandrian text, which was a reconstructed text. Texts from neither of these epochs survive, but citations of them exist in medieval scholias.
Descriptive Bibliography. Callimachus (c. 305–240 BCE) created the first record of Greek manuscripts, Pinakes (Tablets).
Late classical era: the birth of textual commentaries (Servius Honoratus on Virgil, for example). Why is this important? The textual commentaries include quotes of important works and other cultural and historical information that have been otherwise lost. Hugh Cayless offers a good primer on Servius, as well as some thoughts on digital editing, on his blog.
Biblical scholarship: problems of vocalisation, accentuation, and word-division in consonantal Hebrew. Masoretic text (Hebrew and Aramaic copies, c. 7th–9th centuries CE) versus Greek Septuagint translation versus the Dead Sea Scrolls. The Old Testament is far less complicated (textually speaking) than the transmission of the Greek New Testament. Jerome's Vulgate, commissioned by Pope Damascus I in the late 4th century CE, was the first Latin Bible that was based on surviving witnesses (~8000 manuscripts!).
Medieval period saw a period of conservation, copying mostly religious works and trying to reconcile them, as much as possible, with classical (pagan) works. The Caroline Reformation led to a standardised script that made various European national scripts consistent––a significant portion of surviving manuscripts of classical literature is the result of copies made in monasteries with Carolingian script. Meanwhile, Constantinople's holdings of Greek manuscripts were crucial to Italian humanists' serious return to Greek study in the late fourteenth–early fifteenth century.
Copying work transferred from the hands of monks to those of professional scribes, often in universities. The great poet Petrarch's partial reconstruction of Livy's histories was a rigorous editorial project based on manuscript fragments in many medieval repositories. Poggio Bracciolini (1380–1459), acting as papal secretary, found manuscripts all over Europe of prominent classical thinkers. Bracciolini even invented a new humanist script that was far more clear and readable than the prevailing textura (i.e., gothic) script of the day. This is a good moment to reflect on the desire for humanists over time to invent inscription technologies that are consistent, readable, and shareable––a set of values very important to so-called "digital humanities" today.
Another figure worth noting: Lorenzo Valla (1407–57), the great debunker of forgeries: the Donation of Constantine and the letters of Seneca and St. Paul, e.g. He also sought to emend Jerome's Vulgate. His edition, based on Greek and patristic texts, was published by Erasmus in 1505. Similarly, Politian (1454–94) searched for earliest recoverable version of a manuscript––this foreshadowed the genealogical method of plotting a linear path of textual transmission. Politian derived the method of eliminatio codicum descriptorum, the removal of "descriptive" or derived copies as witnesses to an authentic version. This led to the method (very much in use to this day) of stemma codicum, the "family tree" of textual versions.
- Stemmatics: building a family tree by examining scribal errors in multiple manuscript copies. Aldine editions. Example of the Erasmus New Testament. As an example:
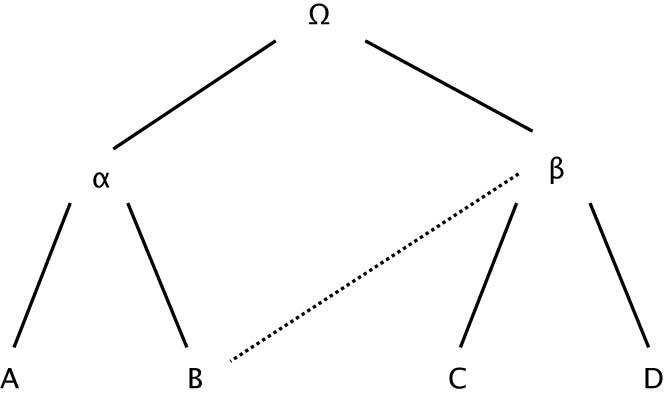 (Source: https://chs.harvard.edu/CHS/article/display/4742.1-textual-criticism-as-applied-to-biblical-and-classical-texts)
(Source: https://chs.harvard.edu/CHS/article/display/4742.1-textual-criticism-as-applied-to-biblical-and-classical-texts)
Philology (OED):
1. Love of learning and literature; the branch of knowledge that deals with the historical, linguistic, interpretative, and critical aspects of literature; literary or classical scholarship. Now chiefly U.S.
3. The branch of knowledge that deals with the structure, historical development, and relationships of languages or language families; the historical study of the phonology and morphology of languages; historical linguistics. See also comparative philology at comparative adj. 1b.
Lachmannian method: identification and evaluation of bibliographic sources with a critical awareness. This comes out of the work of Karl Lachmann (1793–1851), whose 1850 edition of Lucretius claimed that the three extant manuscripts descended from a single archetype. Later witnesses have more errors. Interestingly, Lachmann's Nibelungenlied edition involved more speculation.
Johann Gottfried Eichhorn (1753–1824) and his monumental claim that there was no possibility to find or reconstruct the original or best text in biblical texts, because of all of the layers of copying and linguistic shifts (Einleitung in das Alte Testament, 1780–83).
Friedrich August Wolf (1759–1824) similarly argued in his Prolegomena ad Homerum (1795) that it would be impossible to recover Homeric texts.